In 1993, I wrote out my first business plan for a college class. I called my idea “TeleCom Television”. I drew out plans for things that didn’t exist yet: Netflix-style movies and television on demand, Amazon-style shopping, and Encyclopedia-style information at your fingertips — all accessed by Echo-style voice control to your television. I didn’t follow through on that idea at all because I thought people smarter and better than me had to build them. Back then, not only did these services not exist, we didn’t even have the infrastructure close to what was needed to support these ideas. Today, we have all of the infrastructure and these we have all of these ideas implemented — built by other people. I get to work on building a browser and influencing the internet standards that make all of this possible, but I by no means was a chief player in implementing any of my ideas.
In 2005, I had an idea for a real-time data service for traveling smarter: avoiding cops, road closures, traffic accidents, and other dangers by allowing users to provide the data real-time. In 2006 I let someone talk me out of it. In 2013, a service just as I described called Waze sold to Google for a cool $1.3 billion. I use it everyday knowing it’s pretty much exactly what I envisioned but I don’t collect a dime.
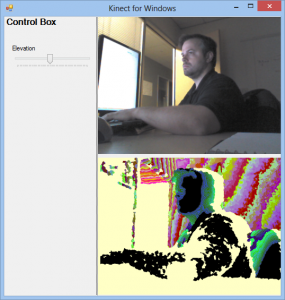
In 2006, my friends Erik Porter, Ernie Booth, and I penned a large paper together on the future of Neal Stephenson-style Virtual/Augmented reality. I thought this required a Microsoft-sized company to build a vision this large. Through Microsoft, we filed a bunch of patents together and set things in motion at Microsoft that have apparently turned out pretty well with Microsoft Kinect, XBOX LIVE Avatar Gear, Project Spark, Microsoft HoloLens and more. Microsoft is benefiting (Kinect opened as the fastest selling electronic device in history) but Erik, Ernie, and I don’t own that vision and our compensation for our ideas was mediocre at best. Worst of all, some other guy gets to own and drive that vision.
I could go on, but I won’t.
I’ve had big ideas in my life. Many of you have similar stories and I’m sure lots of regret from not following up. I’ve had enough with not following my ideas or dreams. I’ve had enough with watching others own the vision for an idea I know I could drive better. I’m tired of watching others get rich on these ideas when I could have a large piece of the pie. So in 2017, I am driving myself to higher motivation. That doesn’t mean I won’t implement and invent new ideas for my company. I’m just going to make sure that I’m in the driver seat of my own vision for where I want to be at this time next year. I’m not going to sit back and be quiet while others implement what I’ve been dreaming of for years.
My goals for the year:
- Automate as much of my daily life as I possibly can. I want my life on auto-pilot so that I can stay in a routine. That may sound rigid, but the truth is, the more automated your life is, the more flexibility you have. This counter-intuitive principle happens because you now have more free-time to spend on what you want and less stress worrying about the things that shouldn’t cause anyone stress.
- Make my job about creating. Creation for me is self-delighting so I want to do more of this. Many people say “I’m going to spend my spare time doing the things I like.” and call that “Work/Life balance.” I’m going to stop trying to “balance” work and life to allow me to work on those passions “in my spare time”. I’m going to make my job more creative and accomplishment-focused. That means I’m going to work on my passions at my job in a way that means when I’m going home, I still get to work on my passions, and that still accumulates to my job. I used to have this and I will have this again.
- Learn from everything/everyone. Learning isn’t just about reading. It’s about putting things into practice. In order to do this you have to stop talking and start listening to others carefully (1-on-1, books, articles, videos, etc) You have to also be able to teach others that topic and you can’t really do that until you’ve done it a good bit yourself. If you catch me being very quiet in a room, it’s not because I’m not interested. It’s because I want to learn what you know and I want to be able to do something practical with that knowledge.
- Iterate constantly and take value early. People that know me know that I tend to focus on putting the full picture together before I unveil. This comes from my “art” days when I didn’t want anyone to look at what I was drawing, painting, etc until I was done. You’ll see me cleaning things up to “ship” frequently and iterating more. The reason? I want to take the value early and use that value to build the next thing or second half of a project more quickly.
That’s all I got for today. I think that’s a lot considering I also haven’t blogged publicly in over a year and 4 months. 🙂

![800xl[1]](/wp-content/uploads/2011/10/800xl1.jpg "800xl[1]")
![packardbell[1]](/wp-content/uploads/2011/10/packardbell1.jpg "packardbell[1]")


